Introduction
Vercre comprises a collection of libraries for issuing, holding, and verifying Verifiable Credentials. It is designed to be modular and flexible, allowing implementers to use only the modules needed.
Libraries
The three top-level Vercre libraries can be used independently or work together for an end-to-end Verifiable Data solution:
vercre-holder— greatly simplifies building cross-platform wallets.vercre-issuer— for building credential issuance APIs.vercre-verifier— for building verifiable presentation APIs.
Shell
Each library requires a 'shell' to wrap and expose functionality. The shell is responsible for handling the application's specific requirements, such as user interface, storage, and network communication.
In the case of the server-side libraries (vercre-issuer and vercre-verifier), the shell is
typically an HTTP server. While in the case of the holder's agent library
(vercre-holder), the shell is typically a mobile or web application.
Example 'shell' implementations can be found in the examples directory.
Implementation
The libraries are written in Rust and are designed to be used in a variety of environments, including WebAssembly, mobile, and server-side applications.
Motivation
When initially exposed to the concepts underpinning decentralized identity, we were excited about its potential to create 'trust-less' digital ecosystems. Privacy-respecting, cryptographically-provable digital credentials would revolutionize the way we interact online.
Immediately after that, we were struck by the range of protocols and the dearth of easy-to-use open-source libraries available to integrate into our applications. Decentralized identity needed to be more accessible for average developers like us.
With the introduction of the OpenID for Verifiable Credential Issuance and Verifiable Presentations standards we believe there is an opportunity to redress this lack and bring Verifiable Credentials further into the mainstream.
Our Contribution
So we thought: why not? Let's see if we can create something for ourselves and others to use to integrate Verifiable Credentials into applications.
We are hoping to contribute to the emergence of decentralized digital trust ecosystems by providing a set of easy-to-use, open-source libraries.
By settling on the OpenID standards, we are making a (safe-ish) bet on the not-inconsiderable base of OpenID-based systems and libraries developed over the years. We want to leverage this existing infrastructure to make it easier for developers to integrate Verifiable Credentials into their applications.
Why Rust?
One of the benefits of a systems programming language like Rust is the ability to control low-level details.
Rust's small binary footprint and efficient memory usage make it well-suited for deployment on small, low-spec devices for a truly distributed infrastructure. And while we have yet to optimize for either, we are confident Rust will be up to the task.
Also, without the need for garbage collection, Rust libraries are eminently well-suited for use by other programming languages via foreign-function interfaces. Non-Rust applications can integrate Vercre without the memory safety risks inherent with other systems programming languages.
Architecture
At its most simple, Vercre is a set of three top-level libraries that support developers in building Verifiable Credential-based applications. That is, applications that can issue, present, and verify credentials — all underpinned by OpenID for Verifiable Credential specifications.
Users bring their own HTTP server(s) and implement provider traits for each library.
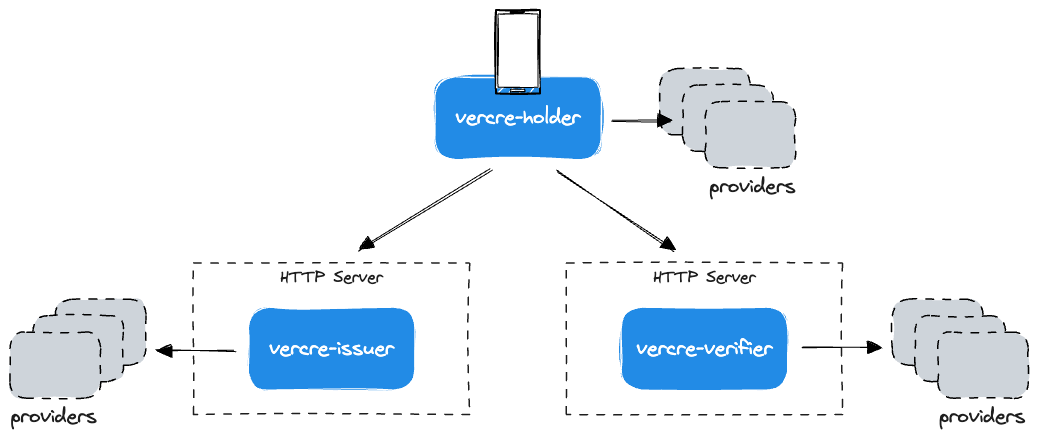
Issuer-Holder-Verifier
Vercre is modelled around the Issuer-Holder-Verifier model — a means of exchanging Verifiable Credential claims, where claim issuance is independent of the process of presenting them to Verifiers.
Each top-level library maps to one of the model's three components:
- vercre-issuer to the Issuer
- vercre-verifier to the Verifier
- vercre-holder to the Holder.
Providers
Each library has a numer of provider traits that users must implement to use the library. Providers allow users to customize the behavior of the library to their needs by bringing their own persistence, state management, secure signing, etc..
We'll cover providers in more depth in the user guides for each library.
Using the Vercre API
The APIs are suitable for demonstration purposes but not yet intended for
production use!
The Vercre API comprises three top-level libraries that form the backbone of OpenID for Verifiable Credentials.
-
Issuer — based on the OpenID for Verifiable Credential Issuance specification, the vercre-issuer library provides an API for issuing Verifiable Credentials.
-
Verifier — based on the OpenID for VerifiablePresentations specification, the vercre-verifier library provides an API for requesting and presenting Verifiable Credentials.
-
Holder — the the vercre-holder library is built against both specifications and can be used to simplify interactions with the issuance and presentation APIs. A typical implementation of the holder library would be a credential wallet.
Design Axioms
While not critical to learning to use the API, the following design axioms might be of some interest in understanding the philosophy we adopted for the development of Vercre libraries.
Do not bake HTTP into the API
While the two core OpenID4VC specifications define an HTTP-based API, we have chosen
not to bake HTTP into the libraries. This decision was made to allow for flexibility of
implementation by library users.
This could be as simple as selecting the most suitable HTTP libraries for the task or as complex as integrating with an existing application. It could even mean using the libraries in a non-HTTP context.
Embrace asynchronous Rust
The libraries are built using asynchronous Rust in order allow for efficient handling of I/O and maximum utility.
Be opinionated
Vercre libraries are opinionated in that they provide a specific way of doing things. Each endpoint accepts a strongly-typed Request object and returns a strongly-typed Response object. This is intended to make the libraries easy to use and reason about.
The Request and Response objects should readily serialize and deserialize to and from compliant JSON objects.
Issuer
Based on the OpenID for Verifiable Credential Issuance specification, the vercre-issuer library provides an API for issuing Verifiable Credentials.
The API is comprised of a set of endpoints, called in sequence to issue a Credential. The sequence is determined both by the flow used to initiate the issuance process as well as such things as whether the issuer defers Credential issuance.
The two primary sequences (or flows) are described below.
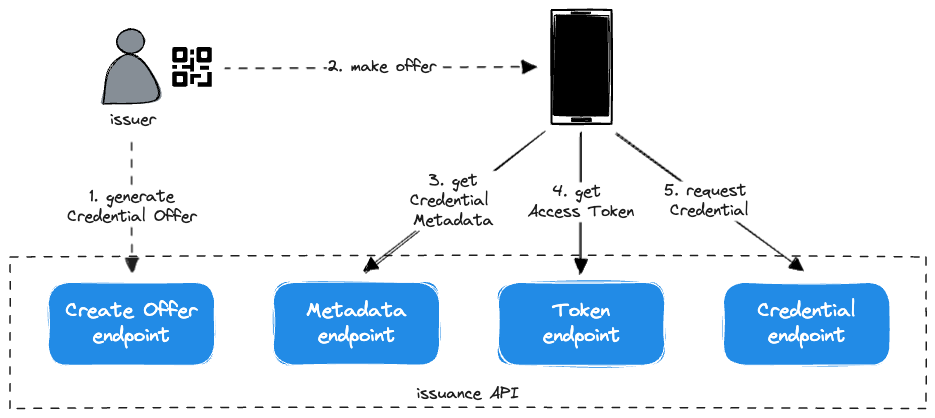
Pre-Authorized Code Flow
The Pre-Authorized Code flow is initiated by the Issuer, who creates a Credential Offer that includes a Pre-Authorized Code. The Offer is "sent" to the Wallet, either directly or by the End-User scanning a QR code or similar.
Currently, we consider this the most common way of initiating Credential issuance and, as a consequence, have invested more in its implementation and ergonimics.
In this flow, the Wallet exchanges the Pre-Authorized Code for an Access Token at the Token Endpoint. The Access Token is then used to request Credential issuance at the Credential Endpoint.
Prior to initiating this flow, the Issuer prepares by authenticating and authorizing the End-User.
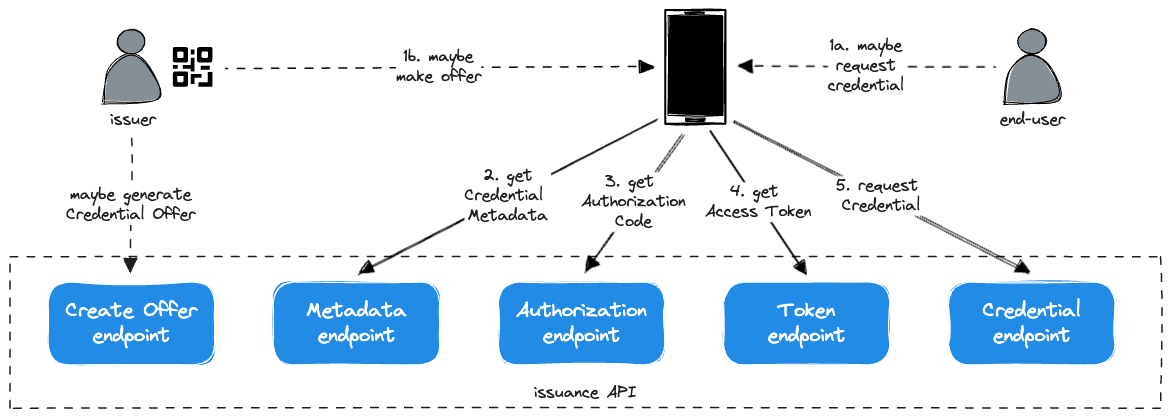
Authorization Code Flow
The Authorization Code flow can be initiated initiated by either the Issuer making a Credential Offer (without a Pre-Authized Code) or the End-User requesting a Credential. In either case, the End-User is unauthorized and must authenticate and authorize before the Credential can issued.
In this case, the Wallet must call the Authorization Endpoint to authorize the End-User. Following authorization, the Wallet exchanges the Authorization Code for an Access Token and the flow continues from Token Endpoint to Credential Endpoint as above.
Implementing the API
In the following sections, we will cover implementing the API, in particular endpoints and providers.
Working example
If you want to skip ahead, this API example provides a naive but complete implementation of the issuance API.
Endpoints
The issuance API is comprised of the a set of endpoints, called in sequence to issue a Credential. The primary endpoints are:
Create Offer— creates Credential Offer used by Issuer to initiate issuanceAuthorization— OAuth 2.0 Authorization endpointToken— OAuth 2.0 Token endpointCredential— issues requested CredentialDeferred Credential— issues Credential when issuance has been 'deferred'Metadata— Issuer and Credential metadataNotification— used by the Wallet to notify of events about issued Credentials
Each endpoint is described in more detail further down.
Exposing Endpoints
In order for Wallets to interact with issuance API, endpoints must be exposed over HTTP.
The following is a minimal example web server exposing endpoints required to support a minimal Pre-Authorized flow example. The example uses axum, but any Rust web server should suffice.
For the sake of brevity, imports, tracing, etc. are omitted. A more complete example can be found in the examples directory.
#[tokio::main]
async fn main() {
// http endpoints
let router = Router::new()
.route("/create_offer", post(create_offer))
.route("/.well-known/openid-credential-issuer", get(metadata))
.route("/token", post(token))
.route("/credential", post(credential))
.with_state(Provider::new()); // <- set up requisite providers in server state
// run the server
let listener = TcpListener::bind("0.0.0.0:8080").await.expect("should bind");
axum::serve(listener, router).await.expect("server should run");
}Endpoint handlers
In our example above, we have defined handlers for each axum route. Each handler
is responsible for converting the HTTP request to a request object that can be passed
to the associated endpoint.
The following example shows how the create_offer handler uses axum to wrap the
heavy lifting of converting the HTTP request body to a CreateOfferRequest object
ready to forward to the endpoint.
Other than forwarding the request to the library, the handler is responsible for setting
the credential_issuer attribute on the request object. This value should come from one
of host, :authority, or Forwarded (if behind a proxy) headers of the HTTP request.
async fn create_offer(
State(provider): State<Provider>, // <- get providers from state
TypedHeader(host): TypedHeader<Host>,
Json(mut req): Json<CreateOfferRequest>, // <- convert request body
) -> AxResult<CreateOfferResponse> {
req.credential_issuer = format!("http://{host}"); // <- set credential issuer
vercre_issuer::create_offer(provider, &req).await.into() // <- forward to library
}More On Endpoints
The following sections describe each endpoint in more detail, highlighting the implementer responsibilities and expected behavior.
Cache-Control
The issuance HTTP API MUST include the HTTP Cache-Control response header
(per RFC2616) with values of "no-store"
and "no-cache" in any responses containing sensitive information. That is, from all
endpoints except the Metadata endpoint.
Create Offer
The Create Offer endpoint is used by the Issuer to create a Credential Offer. The Offer
is used to initiate the issuance process with the Wallet by sending it directly to the
Wallet or by the Wallet scanning a QR code.
Below is an example of a JSON-based Credential Offer for a Pre-Authorized Code Flow.
The JSON is serialized from the CreateOfferResponse struct returned by the endpoint.
{
"credential_issuer": "https://credential-issuer.example.com",
"credential_configuration_ids": [
"UniversityDegree_LDP_VC"
],
"grants": {
"urn:ietf:params:oauth:grant-type:pre-authorized_code": {
"pre-authorized_code": "adhjhdjajkdkhjhdj",
"tx_code": {
"input_mode":"numeric",
"length":6,
"description":"Please provide the one-time code that was sent via e-mail"
}
}
}
}
Metadata
The Metadata endpoint is used by the Wallet to determine the capabilities of the
Issuer and the Credential. The metadata contains information on the Credential Issuer's
technical capabilities, supported Credentials, and (internationalized) display
information.
The metadata MUST be published as a JSON document available at the path formed by
concatenating the Credential Issuer Identifier (HTTP host) with the path
/.well-known/openid-credential-issuer.
For example,
GET /.well-known/openid-credential-issuer HTTP/1.1
Host: credential-issuer.example.com
Accept-Language: fr-ch, fr;q=0.9, en;q=0.8, de;q=0.7, *;q=0.5
Authorization
The Authorization endpoint is used by the Wallet to authorize the End-User for
access to the Credential endpoint. That is, to request issuance of a Credential.
The endpoint is used in the same manner as defined in RFC6749.
N.B. It is the implementers responsibility to authenticate the End-User and ensure their eligibility to receive the requested Credential.
Token
The Token endpoint is used by the Wallet to exchange a Pre-Authorized Code or an
Authorization Code for an Access Token. The Access Token can subsequently be used to
request a Credential at the Credential Endpoint.
The endpoint is used in the same manner as defined in RFC6749.
Credential
The Credential endpoint is used by the Wallet to request Credential issuance.
The Wallet sends the Access Token obtained at the Token Endpoint to this endpoint. The Wallet MAY use the same Access Token to send multiple Credential Requests to request issuance of multiple Credentials of different types bound to the same proof, or multiple Credentials of the same type bound to different proofs.
Deferred Credential
The Deferred Credential endpoint is used by the Wallet to request issuance of a
Credential where issuance was previously deferred (typically to allow for out-of-band
request processing).
Notification
The Notification endpoint is used by the Wallet to notify the Issuer of events about
issued Credentials. The Issuer uses this endpoint to receive notifications about the
status of issued Credentials.
Providers
While exposing and implementing endpoints may be relatively straightforward, the real work is in implementing providers.
Providers are a set of Rust traits that allow the library to outsource data persistence, secure signing, and callback functionality. Each provider requires the library user to implement a corresponding trait, as defined below.
See Vercre's example issuer providers for more detail.
Client Metadata
The ClientMetadata provider is responsible for managing the OAuth 2.0 Client — or Wallet —
metadata on behalf of the library. The provider retrieves Client metadata as well as
dynamic Client (Wallet) registration.
pub trait ClientMetadata: Send + Sync {
fn metadata(&self, client_id: &str) -> impl Future<Output = Result<ClientMetadata>> + Send;
fn register(
&self, client_meta: &ClientMetadata,
) -> impl Future<Output = Result<ClientMetadata>> + Send;
}Issuer Metadata
The IssuerMetadata provider is responsible for making Credential Issuer metadata available to
the issuer library. The library uses this metadata to determine the Issuer's
capabilities as well as returning Credential metadata to the Wallet.
pub trait IssuerMetadata: Send + Sync {
fn metadata(&self, issuer_id: &str) -> impl Future<Output = Result<IssuerMetadata>> + Send;
}Server Metadata
The ServerMetadata provider is responsible for making OAuth 2.0 Authorization Server metadata
available to the issuer library. As with Issuer metadata, the library uses this to
determine capabilities of the Issuer.
pub trait ServerMetadata: Send + Sync {
fn metadata(&self, server_id: &str) -> impl Future<Output = Result<ServerMetadata>> + Send;
}Subject
The Subject provider is responsible for providing the issuer library with information
about the Holder, or end-user the Credential is to be issued to. This information is used
to:
- Determine whether the Holder is authorized to receive the requested Credential.
- Provide the information used to construct the issued Credential (including Credential claims).
pub trait Subject: Send + Sync {
fn authorize(
&self, subject_id: &str, credential_identifier: &str,
) -> impl Future<Output = Result<bool>> + Send;
fn claims(
&self, subject_id: &str, credential: &CredentialDefinition,
) -> impl Future<Output = Result<Claims>> + Send;
}State Manager
As its name implies, StateStore is responsible for temporarily storing and
managing state on behalf of the library.
pub trait StateStore: Send + Sync {
fn put(&self, key: &str, data: Vec<u8>, expiry: DateTime<Utc>,
) -> impl Future<Output = Result<()>> + Send;
fn get(&self, key: &str) -> impl Future<Output = Result<Vec<u8>>> + Send;
fn purge(&self, key: &str) -> impl Future<Output = Result<()>> + Send;
}Data Security
KeyOps provides the library with functionality for signing, encrypting, verifying and decrypting
data by implementing one of the supported signing and verification algorithms. Typically, implementers
will use a key vault, secure enclave, or HSM to manage private keys used for signing.
Supported algorithms are defined in the Credential Issuer metadata.
pub trait KeyOps: Send + Sync {
fn signer(&self, identifier: &str) -> anyhow::Result<impl Signer>;
fn verifier(&self, identifier: &str) -> anyhow::Result<impl Verifier>;
fn encryptor(&self, identifier: &str) -> anyhow::Result<impl Encryptor>;
fn decryptor(&self, identifier: &str) -> anyhow::Result<impl Decryptor>;
}Signer
The Signer trait provides the library with signing functionality for Verifiable Credential issuance.
pub trait Signer: Send + Sync {
fn algorithm(&self) -> Algorithm;
fn verification_method(&self) -> String;
fn sign(&self, msg: &[u8]) -> impl Future<Output = Vec<u8>> + Send {
let v = async { self.try_sign(msg).await.expect("should sign") };
v.into_future()
}
fn try_sign(&self, msg: &[u8]) -> impl Future<Output = anyhow::Result<Vec<u8>>> + Send;
}Verifier
The Verifier trait provides the library with signing verification functionality for Verifiable Credential issuance.
pub trait Verifier: Send + Sync {
fn deref_jwk(&self, did_url: &str)
-> impl Future<Output = anyhow::Result<PublicKeyJwk>> + Send;
}Encryptor
The Encryptor trait provides the library with encryption functionality for Verifiable Credential issuance.
pub trait Encryptor: Send + Sync {
fn encrypt(
&self, plaintext: &[u8], recipient_public_key: &[u8],
) -> impl Future<Output = anyhow::Result<Vec<u8>>> + Send;
fn public_key(&self) -> Vec<u8>;
}Decryptor
The Decryptor trait provides the library with decryption functionality for Verifiable Credential issuance.
pub trait Decryptor: Send + Sync {
fn decrypt(
&self, ciphertext: &[u8], sender_public_key: &[u8],
) -> impl Future<Output = anyhow::Result<Vec<u8>>> + Send;
}Verifier
Based on the OpenID for Verifiable Presentations specification, the vercre-verifier library provides an API for requesting and presenting Verifiable Credentials.
The API is comprised of the a set of endpoints, called in sequence to request presentation of one or more Credentials. While the end result is the same, the sequence varies depending on whether the presentation request is made from the same device as the Wallet (Same-Device Flow) or from a different device (Cross-Device Flow).
Same-Device Flow
Being initiated on the same device as the Wallet, this flow can use simple redirects to pass the Authorization Request and Response objects between the Verifier and the Wallet. Verifiable Presentations are returned to the Verifier in the fragment part of the redirect URI, when Response Mode is fragment.
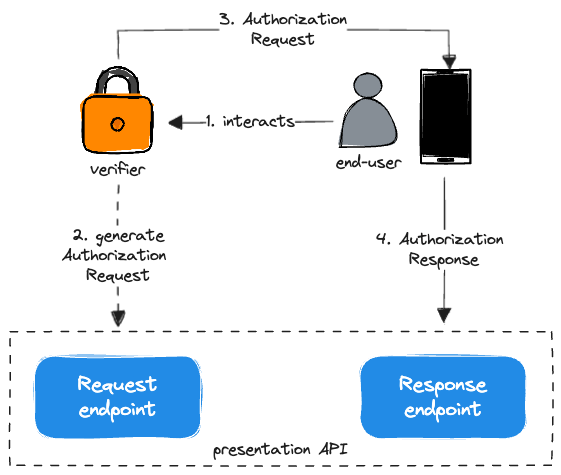
Cross-Device Flow
The Verifier generates an Authorization Request and renders it as a QR code. The End-User then uses the Wallet to scan the QR Code and initiate authorization. The Wallet retrieves the Authorization Request object from the URL referenced in the QR code, processing the contained Presentation Definition.
Once authorized, the Wallet send the resulting Verifiable Presentations directly to the Verifier (using HTTPS POST).
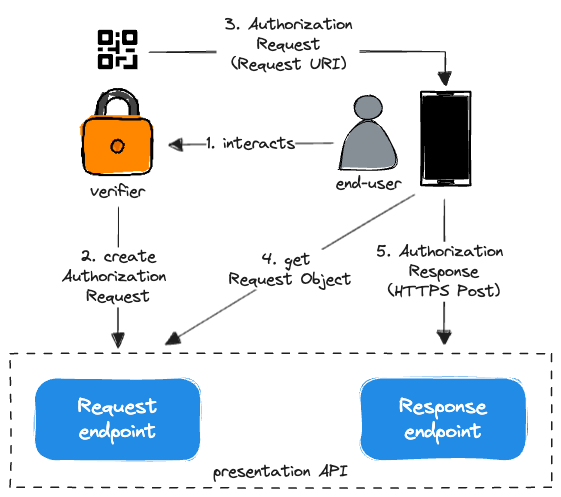
Implementing the API
In the following sections, we will cover implementing the API, in particular endpoints and providers.
Working example
If you want to skip ahead, this API example provides a naive but complete implementation of the presentation API.
Endpoints
The presentation API is comprised of the a set of endpoints, called in sequence to issue a Credential. The primary endpoints are:
-
Create Request— prepares an Authorization Request for the Verifier to send to the Wallet to request authorization (in the form of Verifiable Presentations). -
Authorization Request— used by the Wallet in cross-device flows to retrieve a previously created Authorization Request Object. -
Authorization Response— the endpoint the Wallet sends the Authorization Response (containing Verifiable Presentations) back to the Verifier. -
Verifier Metadata— endpoint to surface Verifier metadata to the Wallet.
Each endpoint is described in more detail below.
Exposing Endpoints
In order for Wallets to interact with presentation API, endpoints must be exposed over HTTP.
The following is a minimal example web server exposing endpoints required to support a minimal Pre-Authorized flow example. The example uses axum, but any Rust web server should suffice.
For the sake of brevity, imports, tracing, etc. are omitted. A more complete example can be found in the examples directory.
#[tokio::main]
async fn main() {
// http endpoints
let router = Router::new()
.route("/create_request", post(create_request))
.route("/request/:client_state", get(request_object))
.route("/callback", get(response))
.route("/post", post(response))
.with_state(Provider::new()); // <- set up requisite providers in server state
// run the server
let listener = TcpListener::bind("0.0.0.0:8080").await.expect("should bind");
axum::serve(listener, router).await.expect("server should run");
}Endpoint handlers
In our example above, we have defined handlers for each axum route. Each handler
is responsible for converting the HTTP request to a request object that can be passed
to the associated endpoint.
The following example shows how the create_request handler uses axum to wrap the
heavy lifting of converting the HTTP request body to a CreateRequestRequest object
ready to forward to the endpoint.
Other than forwarding the request to the library, the handler is responsible for setting
the verifier attribute on the request object. This value should come from one
of host, :authority, or Forwarded (if behind a proxy) headers of the HTTP request.
async fn create_request(
State(endpoint): State<Provider>, // <- get providers from state
TypedHeader(host): TypedHeader<Host>,
Json(mut req): Json<CreateRequestRequest>, // <- convert request body
) -> AxResult<CreateOfferResponse> {
request.client_id = format!("http://{host}"); // <- set verifier
vercre_verifier::create_request(provider, &request).await.into() // <- forward to library
}More On Endpoints
The following sections describe each endpoint in more detail, highlighting the implementer responsibilities and expected behavior.
Cache-Control
The presentation HTTP API MUST include the HTTP Cache-Control response header
(per RFC2616) with values of "no-store"
and "no-cache" in any responses containing sensitive information. That is, from all
endpoints except the Metadata endpoint.
Create Rquest
The Create Request endpoint is used by the Verifier to create an Authorization Request.
The Request is used to initiate the presentation process with the Wallet by sending it
directly to the Wallet as a Request Object or by the Wallet scanning a QR code to get a
URL pointing to the location of the Request Object.
Authorization Request
The Authorization Request endpoint is used by the Wallet to retrieve a previously
created Authorization Request Object.
The Request Object is created by the Verifier when calling the Create Request endpoint to
create an Authorization Request. Instead of sending the Request Object to the Wallet,
the Verifier sends an Authorization Request containing a request_uri which can be
used to retrieve the saved Request Object.
Response
The Response endpoint is where the Wallet sends its response, in the form of an
RFC6749 Authorization Response to the
Verifier's Authorization Request.
If the Authorization Request's Response Type value is "vp_token", the VP Token
is returned in the Authorization Response. When the Response Type value is
"vp_token id_token" and the scope parameter contains "openid", the VP Token is
returned in the Authorization Response alongside a Self-Issued ID Token as defined
in SIOPv2.
If the Response Type value is "code" (Authorization Code Grant Type), the VP Token is provided in the Token Response.
Metadata
The Metadata endpoint is used to make Verifier metadata available to the Wallet.
As the Verifier is a client to the Wallet's Authorization Server, this endpoint returns Client metadata as defined in RFC7591.
Providers
While exposing and implementing endpoints may be relatively straightforward, the real work is in implementing providers.
Providers are a set of Rust traits that allow the library to outsource data persistence, secure signing, and callback functionality. Each provider requires the library user to implement a corresponding trait, as defined below.
See Vercre's example verifier providers for more detail.
Verifier Metadata
The VerifierMetadata provider is responsible for managing the OAuth 2.0 Client — or Verifier —
metadata on behalf of the library. In the case of Verifiable Presentation, the Verifier
is a client of the Authorization Server (the Wallet). The provider retrieves Client (Verifier)
metadata.
pub trait VerifierMetadata: Send + Sync {
fn metadata(&self, client_id: &str) -> impl Future<Output = Result<ClientMetadata>> + Send;
fn register(&self, verifier: &Verifier) -> impl Future<Output = Result<Verifier>> + Send;
}Wallet Metadata
The WalletMetadata provider is responsible for providing the library with information about the Authorization Server — or Wallet.
pub trait WalletMetadata: Send + Sync {
/// Returns the Authorization Server's metadata.
fn metadata(&self, wallet_id: &str) -> impl Future<Output = Result<Wallet>> + Send;
}State Manager
As its name implies, StateStore is responsible for temporarily storing and
managing state on behalf of the library.
pub trait StateStore: Send + Sync {
fn put(&self, key: &str, data: Vec<u8>, expiry: DateTime<Utc>,
) -> impl Future<Output = Result<()>> + Send;
fn get(&self, key: &str) -> impl Future<Output = Result<Vec<u8>>> + Send;
fn purge(&self, key: &str) -> impl Future<Output = Result<()>> + Send;
}Data Security
KeyOps provides the library with functionality for signing, encrypting, verifying and decrypting
data by implementing one of the supported signing and verification algorithms. Typically, implementers
will use a key vault, secure enclave, or HSM to manage private keys used for signing.
Supported algorithms are defined in the Credential Issuer metadata.
pub trait KeyOps: Send + Sync {
fn signer(&self, identifier: &str) -> anyhow::Result<impl Signer>;
fn verifier(&self, identifier: &str) -> anyhow::Result<impl Verifier>;
fn encryptor(&self, identifier: &str) -> anyhow::Result<impl Encryptor>;
fn decryptor(&self, identifier: &str) -> anyhow::Result<impl Decryptor>;
}Signer
The Signer trait provides the library with signing functionality for Verifiable Credential issuance.
pub trait Signer: Send + Sync {
fn algorithm(&self) -> Algorithm;
fn verification_method(&self) -> String;
fn sign(&self, msg: &[u8]) -> impl Future<Output = Vec<u8>> + Send {
let v = async { self.try_sign(msg).await.expect("should sign") };
v.into_future()
}
fn try_sign(&self, msg: &[u8]) -> impl Future<Output = anyhow::Result<Vec<u8>>> + Send;
}Verifier
The Verifier trait provides the library with signing verification functionality for Verifiable Credential issuance.
pub trait Verifier: Send + Sync {
fn deref_jwk(&self, did_url: &str)
-> impl Future<Output = anyhow::Result<PublicKeyJwk>> + Send;
}Encryptor
The Encryptor trait provides the library with encryption functionality for Verifiable Credential issuance.
pub trait Encryptor: Send + Sync {
fn encrypt(
&self, plaintext: &[u8], recipient_public_key: &[u8],
) -> impl Future<Output = anyhow::Result<Vec<u8>>> + Send;
fn public_key(&self) -> Vec<u8>;
}Decryptor
The Decryptor trait provides the library with decryption functionality for Verifiable Credential issuance.
pub trait Decryptor: Send + Sync {
fn decrypt(
&self, ciphertext: &[u8], sender_public_key: &[u8],
) -> impl Future<Output = anyhow::Result<Vec<u8>>> + Send;
}Holder
The vercre-holder crate provides an API for participating in the issuance and presentation of Verifiable Credentials as an agent of the Holder. That is, it can provide the basis for a Wallet for example. It expects the issuer to provide an API that is based on the OpenID for Verifiable Credential Issuance specification and a verifier to provide an API based on the OpenID for Verifiable Presentations specification.
The vercre-holder crate is the third leg of the Verifiable Credential ecosystem alongside vercre-issuer and vercre-verifier. It is recommended you familiarize yourself with these crates to understand how the Holder interacts with the respective issuance and verification flows.
API
In the following sections, we will cover implementing the API, in particular endpoints and providers.
Working example
If you want to skip ahead there is a naive but complete example implementation of a Wallet.
Endpoints
The holder API is comprised of a set of endpoints that orchestrate the issuance or presentation of verifiable credentials. The holder endpoints assume the sequences implied by the verce-issuer and verce-verifier endpoints.
The primary endpoints for issuance are:
Offer- processes an offer of a credential from the issuer and asks the issuer for metadata.Accept- receives acceptance from the holder to accept the offer.PIN- receives a PIN from the holder in cases where the issuer requires one and has sent the PIN via another channel.Get Credential- requests an access token from the issuer and then uses it to request the credential(s) on offer.
The primary endpoints for presentation are:
Request- processes a request for presentation from a verifier.Authorize- receives authorization from the holder to make the presentation.Present- presents the requested credentials to the verifier.
Exposing Endpoints
While the OpenID specification assumes HTTP endpoints for the issuer and verifier services, it may not be a practical protocol for a wallet. However, this does not mean it cannot be used. The repository provides a non-HTTP example (using Tauri) but the following is a minimal example web server exposing endpoints required to support a minimal Pre-Authorized flow example. The example uses axum, but any Rust web server should suffice.
#[tokio::main]
async fn main() {
// http endpoints
let router = Router::new()
.route("/offer", post(offer))
.route("/accept", post(accept))
.route("/pin", post(pin))
.route("/credential", post(credential))
.route("/request", post(request))
.route("/authorize", post(authorize))
.route("/present", post(present))
.with_state(Provider::new()); // <- set up requisite providers in server state
// run the server
let listener = TcpListener::bind("0.0.0.0:8080").await.expect("should bind");
axum::serve(listener, router).await.expect("server should run");
}Endpoint handlers
In our example above, we have defined handlers for each axum route. Each handler is responsible for converting the HTTP request to a request object that can be passed to the associated endpoint.
The following example shows how the offer handler uses axum to wrap the heavy lifting of converting the HTTP request body to an OfferRequest object ready to forward to the endpoint.
async fn offer(
State(provider): State<Provider>, // <- get providers from state
Json(mt req): Json<OfferRequest>, // <- convert request body
) -> AxResult<Issuance> {
vercre_holder::offer(provider, &req).await.into() // <- forward to library
}More On Endpoints
The following sections describe each endpoint in more detail, highlighting the implementer responsibilities and exepected behavior.
Offer
The Offer endpoint receives an offer for a credential from an issuer. This could be implemented, for example, by presenting a QR code to the wallet and passing the retrieved offer to this endpoint. The endpoint will get issuer and credential metadata from the issuer and stash state for subsequent steps in the issuance flow.
The endpoint returns the metadata information so that it can be displayed for consideration of acceptance by the holder.
Accept
The Accept endpoint receives advice from the holder to proceed with issuance.
PIN
The PIN endpoint receives a PIN from the holder in cases where the issuer requires one and has sent the PIN via another channel.
Get Credential
The Get Credential endpoint requests an access token from the issuer and then uses it to request the credential(s) on offer. If required, the PIN will be used in the request. The credentials will be stored in a repository provided by the implementer.
Request
The Request endpoint processes a request for presentation from a verifier. The request can be a fully-formed presentation request or a URI that the wallet can use to retrieve the request from the verifier. In the latter case, using the implementer's provider, the presentation request is retrieved.
The endpoint then looks for the requested credentials in the repository provided by the implementer and returns a rich representation of the presentation request so that it can be considered by the holder for authorization.
Authorize
The Authorize endpoint receives advice from the holder to proceed with presentation.
Present
The Present endpoint presents the requested credentials to the verifier. As required by the OpenID for Verifiable Presentations specification, the credentials are packaged as a Presentation Submission, signed by the implementer's Signer provider.
Providers
In addition to implementing endpoints for a wallet or holder agent, the implementer must also provide a set of providers that the wallet can use to interact with the issuer and verifier, and get or store credentials from a repository.
See Vercre's example holder providers for more detail.
Issuer Client
The IssuerClient provider allows the library to make calls to an issuer's API that implements the OpenID for Verifiable Credential Issuance specification - such as one based on vercre-issuer. The provider is responsible for getting issuer metadata, getting an access token and retrieving the offered credentials.
In addition to the OpenID specification, the W3C data model for a Verifable Credential can contain URLs to logos that are suitable for visual display in, say, a wallet, so the provider should also have a method for retrieving such a logo.
pub trait IssuerClient {
fn get_metadata(
&self, flow_id: &str, req: &MetadataRequest,
) -> impl Future<Output = anyhow::Result<MetadataResponse>> + Send;
fn get_token(
&self, flow_id: &str, req: &TokenRequest,
) -> impl Future<Output = anyhow::Result<TokenResponse>> + Send;
fn get_credential(
&self, flow_id: &str, req: &CredentialRequest,
) -> impl Future<Output = anyhow::Result<CredentialResponse>> + Send;
fn get_logo(
&self, flow_id: &str, logo_url: &str,
) -> impl Future<Output = anyhow::Result<Logo>> + Send;
}Verifier Client
The VerifierClient provider allows the library to make calls to a verifier's API that implements the OpenID for Verifiable Presentations specification - such as one based on vercre-verifier. The provider is responsible for retrieving a presentation request object from a URI if the library receives the request initiation in that format. It also sends the signed presentation submission to the verifier.
pub trait VerifierClient {
fn get_request_object(
&self, flow_id: &str, req: &str,
) -> impl Future<Output = anyhow::Result<RequestObjectResponse>> + Send;
fn present(
&self, flow_id: &str, uri: Option<&str>, presentation: &ResponseRequest,
) -> impl Future<Output = anyhow::Result<ResponseResponse>> + Send;
}Credential Storer
The CredentialStorer provider manages the storage and retrieval of credentials on behalf of the holder. In a wallet, this would be in the device's secure storage, for example.
pub trait CredentialStorer: Send + Sync {
fn save(&self, credential: &Credential) -> impl Future<Output = anyhow::Result<()>> + Send;
fn load(&self, id: &str) -> impl Future<Output = anyhow::Result<Option<Credential>>> + Send;
fn find(
&self, filter: Option<Constraints>,
) -> impl Future<Output = anyhow::Result<Vec<Credential>>> + Send;
fn remove(&self, id: &str) -> impl Future<Output = anyhow::Result<()>> + Send;
}State Manager
As its name implies, StateStore is responsible for temporarily storing and managing state on behalf of the library.
pub trait StateStore: Send + Sync {
fn put(&self, key: &str, data: Vec<u8>, expiry: DateTime<Utc>,
) -> impl Future<Output = Result<()>> + Send;
fn get(&self, key: &str) -> impl Future<Output = Result<Vec<u8>>> + Send;
fn purge(&self, key: &str) -> impl Future<Output = Result<()>> + Send;
}Signer
The Signer trait provides the library with signing functionality for signing presentation submissions.
pub trait Signer: Send + Sync {
fn algorithm(&self) -> Algorithm;
fn verification_method(&self) -> String;
fn sign(&self, msg: &[u8]) -> impl Future<Output = Vec<u8>> + Send {
let v = async { self.try_sign(msg).await.expect("should sign") };
v.into_future()
}
fn try_sign(&self, msg: &[u8]) -> impl Future<Output = anyhow::Result<Vec<u8>>> + Send;
}Verifier
The Verifier trait provides the library with signing verification functionality for Verifiable Credential issuance.
pub trait Verifier: Send + Sync {
fn deref_jwk(&self, did_url: &str)
-> impl Future<Output = anyhow::Result<PublicKeyJwk>> + Send;
}Stability
Vercre's stability is a reflection of the process of change in supported features, platforms, as well as internal structure. This section should provide some insight as to expectations of the maintainers regarding change in Vercre.
For Vercre, the stability of the API is primarily affected by:
-
The process of change — introducing or deprecating features and platforms
-
The number of supported features and platforms — the greater the number, the higher the risk a change will impact some users.
In the following sections , we outline our management of this change — from instigation through to release.
Platform Support
This page is intended to give a high-level overview of Vercre's platform support along with a few Vercre aspirations. For more detail, see the support tiers which has more detail on what is supported and to what extent.
Vercre strives to support hardware that anyone wants to run WebAssembly on. Vercre maintainers support a number of "major" platforms but porting work may be required to support platforms that maintainers are not familiar with.
Out-of-the box Vercre supports:
- Linux: x86_64, aarch64
- MacOS: x86_64, aarch64
- Windows: x86_64
Other platforms such as Android, iOS, and the BSD family of OSes are not yet supported. PRs for porting are welcome and maintainers are happy to add more entries to the CI matrix for these platforms.
TODO: complete this section
Support for #![no_std]
The vercre-issuer crate supports being build on no_std platforms in Rust, but
only for a subset of its compile-time Cargo features. Currently supported features
are:
runtimegccomponent-model
Notably, this does not include the default feature which means that when depending on
Vercre you'll need to set default-features = false.
Vercre's support for no_std requires the embedder to implement the equivalent of a C
header file to indicate how to perform basic OS operations such as allocating virtual
memory. This API can be found as vercre-platform.h in Vercre's release artifacts or at
examples/min-platform/embedding/vercre-platform.h in the source tree. Note that this
API is not guaranteed to be stable at this time, it'll need to be updated when Vercre
is updated.
Vercre's runtime will use the symbols defined in this file meaning that if they're not defined then a link-time error will be generated. Embedders are required to implement these functions in accordance with their documentation to enable Vercre to run on custom platforms.
Support Tiers
Vercre recognises three distinct tiers of platform and feature support. Each tier identifies the level of support that should be provided for a given platform or feature.
The description of these tiers are inspired by the Rust compiler's support tiers for targets with some additional customization for feature support.
This section provides a framework for the evaluation of new features as well as support requires for existing features.
Keep in mind, this is merely a guide and should not be used to "lawyer" a change into Vercre on some technical detail.
Supported Platforms and Features
Tier 1 is classified as the highest level of support, confidence, and correctness for a component. Each tier encompasses all the guarantees of previous tiers.
Features classified under one tier may already meet the criteria for a higher tier. In such situations, it's not intended to use these guidelines to justify removal of a feature.
Guidance is provided for phasing out unmaintained features but it should be clear under what circumstances work "can be avoided" for each tier.
Tier 1 - Production Ready
| Category | Description |
|---|---|
| Target | aarch64-apple-darwin |
| Target 1 | x86_64-unknown-linux-musl |
| Target | wasm32-wasi |
| Example feature | example feature |
Binary artifacts for MUSL can be statically linked, meaning that they are suitable for "run on any linux distribution" style use cases.
Tier 1 is intended to be the highest level of support in Vercre for included features, indicating that they are suitable for production environments. This conveys a high level of confidence within the Vercre project about the included features.
Tier 1 features include:
-
Continuous fuzzing is required for all features. This means that any existing fuzz targets must be running and exercising the new code paths. Where possible differential fuzzing should also be implemented to compare results with other implementations.
-
Continuous fuzzing is required for the architecture of supported targets.
-
CVEs and security releases will be performed as necessary for any bugs found in features and targets.
-
Major changes affecting this tier may require help from maintainers with specialized expertise, but otherwise it should be reasonable to expect most Vercre developers to be able to maintain Tier 1 features.
-
Major changes affecting Tier 1 features require an RFC and prior agreement on the change before an implementation is committed.
A major inclusion point for this tier is intended to be the continuous fuzzing requirement. This implies a significant commitment of resources for fixing issues, resources to execute, etc. Additionally this tier comes with the broadest expectation of "burden on everyone else" in terms of what changes everyone is generally expected to handle.
Features classified as Tier 1 are rarely, if ever, turned off or removed.
Tier 2 - Almost Production Ready
| Category | Description | Missing Tier 1 Requirements |
|---|---|---|
| Target | aarch64-unknown-linux-musl | Continuous fuzzing |
| Target | x86_64-apple-darwin | Continuous fuzzing |
| Target | x86_64-pc-windows-msvc | Continuous fuzzing |
| Target | x86_64-pc-windows-gnu | Clear owner of the target |
| Target | Support for #![no_std] | Support beyond CI checks |
Tier 2 encompasses features and components which are well-maintained, tested well, but don't necessarily meet the stringent criteria for Tier 1. Features in this category may already be "production ready" and safe to use.
Tier 2 features include:
-
Tests are run in CI for the Vercre project for this feature and everything passes. For example a Tier 2 platform runs in CI directly or via emulation. Features are otherwise fully tested on CI.
-
Complete implementations for anything that's part of Tier 1. For example all Tier 2 targets must implement all of the Tier 1 WebAssembly proposals, and all Tier 2 features must be implemented on all Tier 1 targets.
-
Any Vercre developer could be expected to handle minor changes which affect Tier 2 features. For example, if an interface changes, the developer changing the interface should be able to handle the changes for Tier 2 architectures as long as the affected part is relatively minor.
-
For more significant changes, maintainers of a Tier 2 feature should be responsive (reply to requests within a week) and are available to accommodate architectural changes that affect their component. For example more expansive work beyond the previous point where contributors can't easily handle changes are expected to be guided or otherwise implemented by Tier 2 maintainers.
-
Major changes otherwise requiring an RFC that affect Tier 2 components are required to consult Tier 2 maintainers in the course of the RFC. Major changes to Tier 2 components themselves do not require an RFC, however.
Tier 2 features are generally not turned off or disabled for long. Maintainers are required to be responsive to changes and will be notified of any unrelated change which affects their component. It's recommended that if a component breaks for any reason due to an unrelated change that the maintainer either contributes to the PR-in-progress or otherwise has a schedule for the implementation of the feature.
Tier 3 - Not Production Ready
| Category | Description | Missing Tier 2 Requirements |
|---|---|---|
| Target | aarch64-pc-windows-msvc | CI testing, unwinding, full-time maintainer |
| Target | riscv64gc-unknown-linux-gnu | full-time maintainer |
In general, Tier 3 is the baseline for inclusion of code into the Vercre project. However, this does not mean it is the catch-all "if a patch is sent it will be merged" tier. Instead, the goal of this tier is to outline what is expected of contributors adding new features to Vercre which might be experimental at the time of addition.
Tier 3 not a tier where restrictions are releaxed, rather it already implies a significant commitment of effort to a feature being included within Vercre.
Tier 3 features include:
-
Inclusion of a feature does not impose unnecessary maintenance overhead on other components/features. Some examples of additions which would not be accepted are:
- An experimental feature that doubles the CI time for all PRs.
- A change which makes it significantly more difficult to make architectural changes to Vercre's internal implementation.
- A change which makes building Vercre more difficult.
In general Tier 3 features are off-by-default at compile time but still tested-by-default on CI.
-
New features of Vercre cannot have major known bugs at the time of inclusion. Landing a feature requires the feature to be correct and bug-free as best can be evaluated at the time of inclusion. Inevitably, bugs will be found and that's ok, but anything identified during review must be addressed.
-
Code included into the project must be of an acceptable level of quality relative to the rest of the codebase.
-
There must be a path to a feature being finished at the time of inclusion. Adding a new backend, for example, is a significant undertaking which may not be able to be done in a single PR. Partial implementations are acceptable as long as there's a clear path for delivering the completed feature.
-
New components must have a clearly identified owner who is willing to be "on the hook" for review, updates to any internals, etc. For example, a new backend would need to have a maintainer who is willing to respond to changes in interfaces and the needs of Vercre.
Notably, this baseline level of support does not require any degree of testing, fuzzing, or verification. As a result, components classified as Tier 3 are generally not production-ready as they have not yet been 'battle-tested'.
Tier 3 features may be disabled in CI or even removed from the repository. If a Tier 3 feature is preventing development of other features then:
- The owner will be notified.
- If no response is received within one week, the feature will be disabled in CI.
- If no response is received within one month, the feature may be removed from the repository.
Unsupported features and platforms
While this is not an exhaustive list, Vercre does not currently support the following features. While this documents Vercre's current state, it does not mean Vercre does not want to ever support these features; rather design discussion and PRs are welcome for many of the below features to figure out how best to implement them and at least move them to Tier 3 above.
- Target: ARM 32-bit
- Target: FreeBSD
- Target: NetBSD/OpenBSD
- Target: i686 (32-bit Intel targets)
- Target: Android
- Target: MIPS
- Target: SPARC
- Target: PowerPC
- Target: RISC-V 32-bit
Vercre RFCs
Vercre uses an RFC (request for comment) process for instigating major change to any project. We see RFCs as a tool for getting feedback on design and implementation ideas and for consensus-building among stakeholders.
See the Vercre RFC repo for a complete list of RFCs.
What is an RFC?
An RFC lays out a problem along with a proposed solution. To support getting early feedback, RFCs can come in draft or full forms. Draft RFCs should be opened as draft PRs.
In either case, discussion happens by opening a pull request to place the RFC into the
accepted directory.
When is an RFC needed?
Many changes to Vercre projects can and should happen through every-day GitHub processes — issues and pull requests. An RFC is warranted when:
-
There is a change that will significantly affect stakeholders. For example:
- Major architectural changes
- Major new features
- Simple changes that have significant downstream impact
- Changes that could affect guarantees or level of support, e.g. removing support for a target platform
- Changes that could affect mission alignment, e.g. by changing properties of the security model
-
The work is substantial and you want to get early feedback on your approach.
Workflow
Creating and discussing an RFC
-
The RFC process begins by submitting a (possibly draft) pull request, using one of the two templates available in the repository root. The pull request should propose to add a single markdown file into the
acceptedsubdirectory, following the template format, and with a descriptive name. -
The pull request is tagged with a project label designating the project it targets.
-
Once an RFC PR is open, stakeholders and project contributors will discuss it together with the author, raising any points of concern, exploring tradeoffs, and honing the design.
Making a decision
Merge the PR or close it without further action. If the PR is merged, the RFC is considered accepted and the author can begin work on the implementation.
Release Process
Vercre is currently in alpha so the content of this page is subject to change, but we document our release process goals here for now.
This section serves as a high-level summary of Vercre's process. A more detailed description of the process can be found in the contributing section.
Key takeways:
- A new version of Vercre will be made available once a month.
- KeyOps bugs and correctness fixes will be backported to the latest two releases of Vercre and issued as patch releases.
Once a month Vercre will issue a new version. This will be issued with a semver-major version update, such as 0.1.0 to 0.2.0.
A release is scheduled when an automated PR is sent to bump the version on the 5th of every month with the release effected when the PR is merged. The PR typically gets merged within a few days.
Breaking Changes
Each major release of Vercre reserves the right to break both behavior and API backwards-compatibility. This is not expected to happen frequently, however, and any breaking change will follow these criteria:
-
Minor breaking changes, either behavior or with APIs, will be documented in the
CHANGELOG.mdrelease notes. Minor changes will require some degree of consensus but are not required to go through the entire RFC process. -
Major breaking changes, such as major refactorings to the API, will be required to go through the RFC process. These changes are intended to be broadly communicated to those interested and provides an opportunity to give feedback about embeddings. Release notes will clearly indicate if any major breaking changes through accepted RFCs are included in a release.
Patching
Patch releases of Vercre will only be issued for security and critical correctness issues for on-by-default behavior in the previous releases. If Vercre is currently at version 0.2.0 then 0.2.1 and 0.1.1 will be issued as patch releases if a bug is found. Patch releases are guaranteed to maintain API and behavior backwards-compatibility and are intended to be trivial for users to upgrade to.
What's released?
Currently, Vercre's release process encompasses the three top-level vercre-xxx Rust
crates.
Other projects maintained by the Vercre maintainers will also likely be released, with the same version numbers, with the main Vercre project soon after a release is made.
KeyOps
TODO: include summary content here...
Disclosure Policy
This section addresses the security disclosure policy for Vercre projects.
The security report is received and is assigned a primary handler. This person will coordinate the fix and release process. The problem is confirmed and a list of all affected versions is determined. Code is audited to find any potential similar problems. Fixes are prepared for all releases which are still under maintenance. These fixes are not committed to the public repository but rather held locally pending the announcement.
A suggested embargo date for this vulnerability is chosen and a CVE (Common Vulnerabilities and Exposures) is requested for the vulnerability.
A pre-notification may be published on the security announcements mailing list, providing information about affected projects, severity, and the embargo date.
On the embargo date, the Vercre security mailing list is sent a copy of the announcement. The changes are pushed to the public repository and new builds are deployed.
Typically the embargo date will be set 72 hours from the time the CVE is issued. However, this may vary depending on the severity of the bug or difficulty in applying a fix.
This process can take some time, especially when coordination is required with maintainers of other projects. Every effort will be made to handle the bug in as timely a manner as possible; however, it’s important that we follow the release process above to ensure that the disclosure is handled in a consistent manner.
Project maintainers are encouraged to write a post-mortem for the Vercre blog, detailing the vulnerability and steps being taken to identify and prevent similar vulnerabilities in the future.
Publishing KeyOps Updates
KeyOps notifications will be distributed via the following methods.
- Zulip: https://vercre.zulipchat.com/#channels/440231/security-updates/
- Email: TODO: add mailing list information...
KeyOps Bugs
If you are unsure whether an issue is a security vulnerability, always err on the side of caution and report it as a security vulnerability!
Bugs must affect a tier 1 platform or feature to be considered a security vulnerability.
KeyOps of the core libraries is paramount. Anything that undermines their ability to function correctly and securely is a security vulnerability.
On the other hand, execution that diverges from OpenID semantics (such as naming, lack of support for a particular RFC, etc.) are not considered security vulnerabilities so long as they do not guarantees implied by the existing implementation.
Denials of service when executing are considered security vulnerabilities. For example, a Vercre endpoint that goes into an infinite loop that never yields is considered a security vulnerability.
Any kind of memory unsafety (e.g. use-after-free bugs, out-of-bounds memory accesses, etc...) is always a security vulnerability.
Cheat Sheet: Is it a security vulnerability?
| Type of bug | |
|---|---|
| Yes |
| Yes |
| Yes |
| Yes |
| Yes |
| Yes |
| Yes |
| Yes |
| Yes |
| Yes |
| Yes |
| Yes |
| Yes |
| Yes |
| No |
| No |
| No |
N.B. We still want to fix every bug mentioned above even if it is not a security vulnerability! We appreciate when issues are filed for non-vulnerability bugs, particularly when they come with test cases and steps to reproduce!
Contributing
We're excited to work on Vercre and hope you will be too! This guide should help you get up and running with Vercre development. But first, make sure you've read our Code of Conduct.
Vercre is ambitious, with much work to be done to achieve full compliance with the core OpenID specifications. And while we're confident we can achieve our goals, we see many opportunities for others to get involved and help get there more quickly.
Join Our Chat
We chat about Vercre development on Zulip — join us!.
If you're having trouble building Vercre, aren't sure why a test is failing, or have any other questions, feel free to ask on Zulip. Not everything we hope to do with these projects is reflected in the code or documentation yet, so if you see things that seem missing or that don't make sense, or even that just don't work the way you expect them to, we're also interested to hear about that!
As always, you're more than welcome to open an issue too!
Finally, we have bi-weekly project meetings, hosted on Zoom, for Vercre. For more information, see our meetings agendas/minutes repository. Please feel free to contact us via Zulip if you're interested in joining!
Finding Something to Hack On
If you're looking for something to do, these are great places to start:
Issues labeled "good first issue" — these issues tend to be simple, what needs to be done is well known, and are good for new contributors to tackle. The goal is to learn Vercre's development workflow and make sure that you can build and test Vercre.
Issues labeled "help wanted" — these are issues that we need a little help with!
If you're unsure if an issue is a good fit for you or not, feel free to ask in a comment on the issue, or in chat.
Mentoring
We're happy to mentor people, whether you're learning Rust, learning about Verifiable Credentials, Credential wallets or anything else that piques your interest.
We categorize issues in the issue tracker using a tag scheme inspired by Rust's issue tags. For example, the E-easy marks good beginner issues, and E-rust marks issues which likely require some familiarity with Rust, though not necessarily Verifiable Credentials.
Also, we encourage people to just look around and find things they're interested in. This a good time to get involved, as there aren't a lot of things set in stone yet.
Building
This section describes everything required to build and run Vercre.
Prerequisites
Before we can actually build Vercre, we'll need to make sure these things are installed first.
The Rust Toolchain
Install the Rust toolchain here. This
includes rustup, cargo, rustc, etc...
Building vercre Libraries
To make an unoptimized, debug build of the vercre CLI tool, go to the root
of the repository and run this command:
cargo build
The built executable will be located at target/debug/vercre.
To make an optimized build, run this command in the root of the repository:
cargo build --release
The built executable will be located at target/release/vercre.
You can also build and run a local vercre CLI by replacing cargo build
with cargo run.
Building Other Vercre Crates
You can build any of the Vercre crates by appending -p vercre-whatever to
the cargo build invocation. For example, to build the vercre-holder crate,
execute this command:
cargo build -p vercre-holder
Alternatively, you can cd into the crate's directory, and run cargo build
there, without needing to supply the -p flag:
cd vercre-holder
cargo build
Testing
This section describes how to run Vercre's tests and add new tests.
Before continuing, make sure you can build Vercre successfully. Can't run the tests if you can't build it!
Installing wasm32 Targets
To compile the tests, you'll need the wasm32-wasip1 and
wasm32-unknown-unknown targets installed, which, assuming you're using
rustup.rs to manage your Rust versions, can be done as
follows:
rustup target add wasm32-wasip1
Running All Tests
To run all of Vercre's tests, execute this command:
cargo test --workspace
You can also exclude a particular crate from testing with --exclude. For
example, if you want to avoid testing the vercre-verifier crate:
cargo test --workspace --exclude vercre-verifier
Testing a Specific Crate
You can test a particular Vercre crate with cargo test -p vercre-whatever. For example, to test the vercre-issuer crate, execute
this command:
cargo test -p vercre-issuer
Alternatively, you can cd into the crate's directory, and run cargo test
there, without needing to supply the -p flag:
cd vercre-issuer/
cargo test
Adding New Tests
Adding Rust's #[test]-Style Tests
For very "unit-y" tests, we add test modules in the same .rs file as the
code that is being tested. These test modules are configured to only get
compiled during testing with #[cfg(test)].
#![allow(unused)] fn main() { // some code... #[cfg(test)] mod tests { use super::*; #[test] fn some_test_for_that_code() { // ... } } }
If you're writing a unit test and a test module doesn't already exist, you can
create one.
For more "integration-y" tests, we create a tests directory within the crate,
and put the tests inside there. For example, there are various end-to-end flow tests at vercre-holder/tests. Always feel free to
add a tests directory to a crate, if you want to add a new test and there
aren't any existing tests.
Coding guidelines
For the most part, Vercre follows common Rust conventions and pull request (PR) workflows, though we do have a few additional things to be aware of.
rustfmt
All PRs must be formatted according to rustfmt, and this is checked in the continuous integration tests. You can format code locally with:
$ cargo fmt
at the root of the repository. You can find more information about rustfmt online too, such as how to configure your editor.
Minimum Supported rustc Version
Vercre supports the latest three stable releases of Rust. This means that if the latest version of Rust is 1.78.0 then Vercre supports Rust 1.76.0, 1.77.0, and 1.78.0. CI will test by default with 1.78.0 and there will be one job running the full test suite on Linux x86_64 on 1.76.0.
Some of the CI jobs depend on nightly Rust, for example to run rustdoc with nightly features, however these use pinned versions in CI that are updated periodically and the general repository does not depend on nightly features.
Updating Vercre's MSRV is done by editing the rust-version field in the
workspace root's Cargo.toml
Dependencies of Vercre
Vercre have a higher threshold than default for adding
dependencies to the project. All dependencies are required to be "vetted"
through the cargo vet tool. This is
checked on CI and will run on all modifications to Cargo.lock.
A "vet" for Vercre is not a meticulous code review of a dependency for correctness but rather it is a statement that the crate does not contain malicious code and is safe for us to run during development and (optionally) users to run when they run Vercre themselves. Vercre's vet entries are used by other organizations which means that this isn't simply for our own personal use. Vercre additionally uses vet entries from other organizations as well which means we don't have to vet everything ourselves.
New vet entries are required to be made by trusted contributors to Vercre.
This is all configured in the supply-chain folder of Vercre. These files
generally aren't hand-edited though and are instead managed through the cargo vet tool itself. Note that our supply-chain/audits.toml additionally contains
entries which indicates that authors are trusted as opposed to vets of
individual crates. This lowers the burden of updating version of a crate from a
trusted author.
When put together this means that contributions to Vercre which update existing dependencies or add new dependencies will not be mergeable by default (CI will fail). This is expected from our project's configuration and this situation will be handled one of a few ways:
Note that this process is not in place to prevent new dependencies or prevent
updates, but rather it ensures that development of Vercre is done with a
trusted set of code that has been reviewed by trusted parties. We welcome
dependency updates and new functionality, so please don't be too alarmed when
contributing and seeing a failure of cargo vet on CI!
cargo vet for Contributors
If you're a contributor to Vercre and you've landed on this documentation, hello and thanks for your contribution! Here's some guidelines for changing the set of dependencies in Vercre:
-
If a new dependency is being added it might be worth trying to slim down what's required or avoiding the dependency altogether. Avoiding new dependencies is best when reasonable, but it is not always reasonable to do so. This is left to the judgement of the author and reviewer.
-
When updating dependencies this should be done for a specific purpose relevant to the PR-at-hand. For example if the PR implements a new feature then the dependency update should be required for the new feature. Otherwise it's best to leave dependency updates to their own PRs. It's ok to update dependencies "just for the update" but we prefer to have that as separate PRs.
Dependency additions or updates require action on behalf of project maintainers
so we ask that you don't run cargo vet yourself or update the supply-chain
folder yourself. Instead a maintainer will review your PR and perform the cargo vet entries themselves. Reviewers will typically make a separate pull request
to add cargo vet entries and once that lands yours will be added to the queue.
cargo vet for Maintainers
Maintainers of Vercre are required to explicitly vet and approve all
dependency updates and modifications to Vercre. This means that when reviewing
a PR you should ensure that contributors are not modifying the supply-chain
directory themselves outside of commits authored by other maintainers. Otherwise
though to add vet entries this is done through one of a few methods:
-
For a PR where maintainers themselves are modifying dependencies the
cargo vetentries can be included inline with the PR itself by the author. The reviewer knows that the author of the PR is themself a maintainer. -
PRs that "just update dependencies" are ok to have at any time. You can do this in preparation for a future feature or for a future contributor. This more-or-less is the same as the previous categories.
-
For contributors who should not add vet entries themselves maintainers should review the PR and add vet entries either in a separate PR or as part of the contributor's PR itself. As a separate PR you'll check out the branch, run
cargo vet, then rebase away the contributor's commits and push yourcargo vetcommit alone to merge. For pushing directly to the contributor's own PR be sure to read the notes below.
Note for the last case it's important to ensure that if you push directly to a contributor's PR any future updates pushed by the contributor either contain or don't overwrite your vet entries. Also verify that if the PR branch is rebased or force-pushed, the details of your previously pushed vetting remain the same: e.g., versions were not bumped and descriptive reasons remain the same. If pushing a vetting commit to a contributor's PR and also asking for more changes, request that the contributor make the requested fixes in an additional commit rather than force-pushing a rewritten history, so your existing vetting commit remains untouched. These guidelines make it easier to verify no tampering has occurred.
Policy for adding cargo vet entries
For maintainers this is intended to document the project's policy on adding
cargo vet entries. The goal of this policy is to not make dependency updates
so onerous that they never happen while still achieving much of the intended
benefit of cargo vet in protection against supply-chain style attacks.
-
For dependencies that receive at least 10,000 downloads a day on crates.io it's ok to add an entry to
exemptionsinsupply-chain/config.toml. This does not require careful review or review at all of these dependencies. The assumption here is that a supply chain attack against a popular crate is statistically likely to be discovered relatively quickly. Changes tomainin Vercre take at least 2 weeks to be released due to our release process, so the assumption is that popular crates that are victim of a supply chain attack would be discovered during this time. This policy additionally greatly helps when updating dependencies on popular crates that are common to see without increasing the burden too much on maintainers. -
For other dependencies a manual vet is required. The
cargo vettool will assist in adding a vet by pointing you towards the source code, as published on crates.io, to be browsed online. Manual review should be done to ensure that "nothing nefarious" is happening. For exampleunsafeshould be inspected as well as use of ambient system capabilities such asstd::fs,std::net, orstd::process, and build scripts. Note that you're not reviewing for correctness, instead only for whether a supply-chain attack appears to be present.
This policy intends to strike a rough balance between usability and security.
It's always recommended to add vet entries where possible, but the first bullet
above can be used to update an exemptions entry or add a new entry. Note that
when the "popular threshold" is used do not add a vet entry because the
crate is, in fact, not vetted. This is required to go through an
[[exemptions]] entry.
Development Process
We use issues for asking questions (open one here!) and tracking bugs and unimplemented features, and pull requests (PRs) for tracking and reviewing code submissions.
Before submitting a PR
Consider opening an issue to talk about it. PRs without corresponding issues are appropriate for fairly narrow technical matters, not for fixes to user-facing bugs or for feature implementations, especially when those features might have multiple implementation strategies that usefully could be discussed.
Our issue templates might help you through the process.
When submitting PRs
-
Please answer the questions in the pull request template. They are the minimum information we need to know in order to understand your changes.
-
Write clear commit messages that start with a one-line summary of the change (and if it's difficult to summarize in one line, consider splitting the change into multiple PRs), optionally followed by additional context. Good things to mention include which areas of the code are affected, which features are affected, and anything that reviewers might want to pay special attention to.
-
If there is code which needs explanation, prefer to put the explanation in a comment in the code, or in documentation, rather than in the commit message. Commit messages should explain why the new version is better than the old.
-
Please include new test cases that cover your changes, if you can. If you're not sure how to do that, we'll help you during our review process.
-
For pull requests that fix existing issues, use issue keywords. Note that not all pull requests need to have accompanying issues.
-
When updating your pull request, please make sure to re-request review if the request has been cancelled.
Focused commits or squashing
We are not picky about how your git commits are structured. When we merge your PR, we will squash all of your commits into one, so it's okay if you add fixes in new commits.
We appreciate it if you can organize your work into separate commits which each make one focused change, because then we can more easily understand your changes during review. But we don't require this.
Once someone has reviewed your PR, it's easier for us if you don't rebase it when making further changes. Instead, at that point we prefer that you make new commits on top of the already-reviewed work.
That said, sometimes we may need to ask you to rebase for various technical reasons. If you need help doing that, please ask!
Review and merge
Anyone may submit a pull request, and anyone may comment on or review others' pull requests. However, one review from somebody in the Core Team is required before the Core Team merges it.
Even Core Team members must create PRs and get review from another Core Team member for every change, including minor work items such as version bumps, removing warnings, etc.
Maintainer Guidelines
This section describes procedures and expectations for Core Team members. It may be of interest if you just want to understand how we work, or if you are joining the Core Team yourself.
Code Review
We only merge changes submitted as GitHub Pull Requests, and only after they've been approved by at least one Core Team reviewer who did not author the PR. This section covers expectations for the people performing those reviews. These guidelines are in addition to expectations which apply to everyone in the community, such as following the Code of Conduct.
It is our goal to respond to every contribution in a timely fashion. Although we make no guarantees, we aim to usually provide some kind of response within about one business day.
That's important because we appreciate all the contributions we receive, made by a diverse collection of people from all over the world. One way to show our appreciation, and our respect for the effort that goes into contributing to this project, is by not keeping contributors waiting. It's no fun to submit a pull request and then sit around wondering if anyone is ever going to look at it.
That does not mean we will review every PR promptly, let alone merge them. Some contributions have needed weeks of discussion and changes before they were ready to merge. For some other contributions, we've had to conclude that we could not merge them, no matter how much we appreciate the effort that went into them.
What this does mean is that we will communicate with each contributor to set expectations around the review process. Some examples of good communication are:
-
"I intend to review this but I can't yet. Please leave me a message if I haven't responded by (a specific date in the near future)."
-
"I think (a specific other contributor) should review this."
-
"I'm having difficulty reviewing this PR because of (a specific reason, if it's something the contributor might reasonably be able to help with). Are you able to change that? If not, I'll ask my colleagues for help (or some other concrete resolution)."
If you are able to quickly review the PR, of course, you can just do that.
You can find open Vercre pull requests for which your review has been requested with this search:
https://github.com/vercre/vercre/pulls?q=is:open+type:pr+user-review-requested:@me
Auto-assigned reviewers
We automatically assign a reviewer to every newly opened pull request. We do this to avoid the problem of diffusion of responsibility, where everyone thinks somebody else will respond to the PR, so nobody does.
To be in the pool of auto-assigned reviewers, a Core Team member must commit to following the above goals and guidelines around communicating in a timely fashion.
We don't ask everyone to make this commitment. In particular, we don't believe it's fair to expect quick responses from unpaid contributors, although we gratefully accept any review work they do have time to contribute.
If you are in the auto-assignment pool, remember: You are not necessarily expected to review the pull requests which are assigned to you. Your only responsibility is to ensure that contributors know what to expect from us, and to arrange that somebody reviews each PR.
TODO: Review this hidden div content
We have several different teams that reviewers may be auto-assigned from. You
should be in teams where you are likely to know who to re-assign a PR to, if you
can't review it yourself. The teams are determined by the CODEOWNERS file at
the root of the Vercre repository. But despite the name, membership in these
teams is not about who is an authority or "owner" in a particular area. So
rather than creating a team for each fine-grained division in the repository
such as individual target architectures or WASI extensions, we use a few
coarse-grained teams:
- core-utils-reviewers: Vercre's core functionality
- vercre-fuzz-reviewers: Fuzz testing targets
- vercre-default-reviewers: Anything else, including CI and documentation
Ideally, auto-assigned reviewers should be attending the regular Vercre meetings, as appropriate for the areas they're reviewing. This is to help these reviewers stay aware of who is working on what, to more easily hand off PRs to the most relevant reviewer for the work. However, this is only advice, not a hard requirement.
If you are not sure who to hand off a PR review to, you can look at GitHub's
suggestions for reviewers, or look at git log for the paths that the PR
affects. You can also just ask other Core Team members for advice.
General advice
This is a collection of general advice for people who are reviewing pull requests. Feel free to take any that you find works for you and ignore the rest. You can also open pull requests to suggest more references for this section.
The Gentle Art of Patch Review suggests a "Three-Phase Contribution Review" process:
- Is the idea behind the contribution sound?
- Is the contribution architected correctly?
- Is the contribution polished?
Phase one should be a quick check for whether the pull request should move forward at all, or needs a significantly different approach. If it needs significant changes or is not going to be accepted, there's no point reviewing in detail until those issues are addressed.
On the other end, it's a good idea to defer reviewing for typos or bikeshedding about variable names until phase three. If there need to be significant structural changes, entire paragraphs or functions might disappear, and then any minor errors that were in them won't matter.
The full essay has much more advice and is recommended reading.
Releasing Updates
Overview
Overall, the Vercre's release process favours bringing new features to market frequently, while minimizing the risk of releasing a broken version. It draws heavily on the Rust release process, which is well-documented and understood.
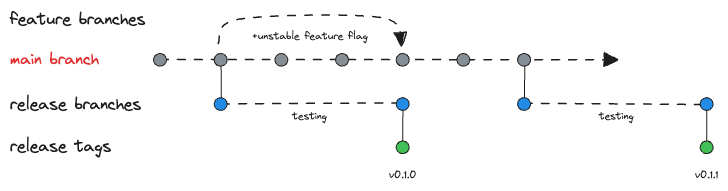
Core tenets
The release process starts as soon as a change is identified. That is, the decision to release is not a separate step at the end of development, but rather a natural consequence of bringing a change to market.
TLDR:
mainis the source of truth.- Development is undertaken on
featurebranches and is considered complete when requirements have been met and CI checks pass. - Completed features are merged back into
main, gated behind a "feature flag". - A short-lived
releasebranch is created for testing and release preparation with any changes merged back intomain. - Once ready, a release is tagged, published, and the branch deleted.
main branch
The main branch is the source of truth. It should always be in a releasable state, and is the basis for all development. While new development is undertaken on feature branches, changes should be merged as soon as practicable, protected behind a temporary feature flag for the change.
Feature branches
Development is undertaken on feature branches. Branches should be as short-lived as possible, and are deleted once the change is merged back into main.
If possible, larger changes should be broken down into smaller, more manageable changes, and developed on separate branches.
Every feature change should be added to the manually curated CHANGELOG.md for the relevant crate.
Publishing a release
The publishing process is initiated by creating a new, short-lived, release branch from main. The branch should be named for the release version, e.g. release-v0.2.0.
Create a new branch from main and check out:
git checkout -b release-v0.2.0
The new version number can be determined by running a a semver check on the codebase to establish the whether this is a major, minor, or patch release.
cargo make semver
Comprehensive integration testing is undertaken on this branch, with any changes merged back into main. Once the release is ready, the code is tagged, published, and the branch deleted.
Create release tag and push the branch and tag to the remote repository:
git tag v0.2.0 -m "v0.2.0 release"
# push new branch
git push --set-upstream origin release-v0.2.0
git push --tags
TODO: Add a section on how to create a release on Github.
cargo make release minor
Changelog
All notable changes should be documented in the project's CHANGELOG.md file. Per Keep a Changelog recommendations, changes are a manually documented, high-level summary of changes in a release.
Dry run
Set the release level using one of release, major, minor, patch, alpha, beta, rc
For example, to release a minor version:
cargo make release minor
Publish
Release to crates.io:
cargo make publish minor
Governance
TODO: Add governance information...
Code of Conduct
Note: this Code of Conduct pertains to individuals' behavior. Please also see the Organizational Code of Conduct.
Our Pledge
In the interest of fostering an open and welcoming environment, we as contributors and maintainers pledge to making participation in our project and our community a harassment-free experience for everyone, regardless of age, body size, disability, ethnicity, gender identity and expression, level of experience, nationality, personal appearance, race, religion, or sexual identity and orientation.
Our Standards
Examples of behavior that contributes to creating a positive environment include:
- Using welcoming and inclusive language
- Being respectful of differing viewpoints and experiences
- Gracefully accepting constructive criticism
- Focusing on what is best for the community
- Showing empathy towards other community members
Examples of unacceptable behavior by participants include:
- The use of sexualized language or imagery and unwelcome sexual attention or advances
- Trolling, insulting/derogatory comments, and personal or political attacks
- Public or private harassment
- Publishing others' private information, such as a physical or electronic address, without explicit permission
- Other conduct which could reasonably be considered inappropriate in a professional setting
Our Responsibilities
Project maintainers are responsible for clarifying the standards of acceptable behavior and are expected to take appropriate and fair corrective action in response to any instances of unacceptable behavior.
Project maintainers have the right and responsibility to remove, edit, or reject comments, commits, code, wiki edits, issues, and other contributions that are not aligned to this Code of Conduct, or to ban temporarily or permanently any contributor for other behaviors that they deem inappropriate, threatening, offensive, or harmful.
Scope
This Code of Conduct applies both within project spaces and in public spaces when an individual is representing the project or its community. Examples of representing a project or community include using an official project e-mail address, posting via an official social media account, or acting as an appointed representative at an online or offline event. Representation of a project may be further defined and clarified by project maintainers.
Enforcement
Instances of abusive, harassing, or otherwise unacceptable behavior may be reported by contacting the Vercre CoC team at report@vercre.io. The CoC team will review and investigate all complaints, and will respond in a way that it deems appropriate to the circumstances. The CoC team is obligated to maintain confidentiality with regard to the reporter of an incident. Further details of specific enforcement policies may be posted separately.
Project maintainers who do not follow or enforce the Code of Conduct in good faith may face temporary or permanent repercussions as determined by other members of Vercre's leadership.
Attribution
This Code of Conduct is adapted from the Contributor Covenant, version 1.4, available at http://contributor-covenant.org/version/1/4/